Mastering Machine Learning Techniques for Time Series Forecasting in Finance
In the rapidly evolving landscape of global financial markets, the ability to accurately forecast future trends is not just an advantage; it’s a necessity. This comprehensive guide delves into the cutting-edge realm of machine learning techniques for time series forecasting in finance, offering a deep dive into how these powerful algorithms are revolutionizing predictive analytics. From understanding market volatility to optimizing investment strategies, machine learning provides sophisticated tools for deciphering complex financial data, empowering traders, analysts, and quantitative researchers to make more informed decisions and gain a competitive edge. Explore the methodologies, practical applications, and critical considerations essential for leveraging AI in the dynamic world of finance.
The Imperative of Time Series Forecasting in Finance
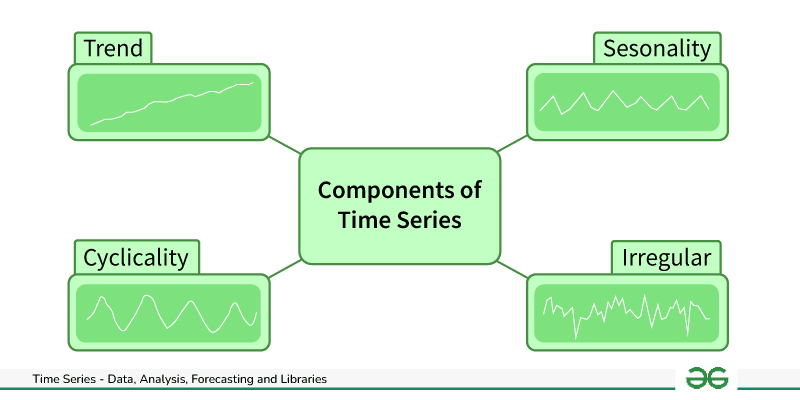
The financial sector operates on the pulse of time. Every transaction, every price movement, and every economic indicator forms a time series, a sequence of data points indexed in time order. The inherent non-stationarity, high noise, and often chaotic nature of financial data make traditional statistical methods challenging to apply effectively. This is where machine learning shines, offering robust frameworks to identify intricate patterns and dependencies that might be invisible to the human eye or simpler models. Accurate time series forecasting is critical for a multitude of financial activities, including risk management, derivative pricing, portfolio optimization, and developing advanced algorithmic trading strategies.
Why Traditional Models Fall Short
Historically, econometric models like ARIMA (AutoRegressive Integrated Moving Average) and GARCH (Generalized AutoRegressive Conditional Heteroskedasticity) have been staples for financial time series analysis. While foundational, they often struggle with the inherent non-linearity and high dimensionality of modern financial data. The advent of big data and increased computational power has paved the way for machine learning to overcome these limitations, providing more adaptable and powerful tools for prediction.
Fundamental Machine Learning Techniques for Financial Time Series
Machine learning offers a diverse toolkit for time series analysis. The choice of technique often depends on the specific problem, data characteristics, and desired interpretability.
Regression Models & Their Evolution
- Linear Regression: While simplistic, it serves as a baseline. It models the linear relationship between a dependent variable (e.g., stock price) and one or more independent variables (e.g., past prices, trading volume). Its primary limitation in finance is its inability to capture non-linear relationships and complex interactions.
- Ridge and Lasso Regression: These are regularized versions of linear regression, designed to prevent overfitting by penalizing large coefficients. They are useful for feature selection and handling multicollinearity, which is common in financial datasets with many correlated features.
Tree-Based Models: Random Forests and Gradient Boosting
Tree-based models are particularly powerful for financial time series due to their ability to capture non-linear relationships and interactions between features without requiring extensive data preprocessing like normalization. They are also less sensitive to outliers.
- Random Forests: An ensemble method that builds multiple decision trees during training and outputs the mean prediction (for regression) or mode (for classification) of the individual trees. They are robust against overfitting and provide good estimates of feature importance, which is invaluable for understanding which factors drive financial movements.
- Gradient Boosting Machines (GBMs): These build trees sequentially, with each new tree correcting the errors of the previous ones. Popular implementations like XGBoost, LightGBM, and CatBoost are highly efficient and effective, often winning machine learning competitions. They are widely used in quantitative finance for tasks like credit scoring, fraud detection, and predicting price movements due to their high predictive power.
Support Vector Machines (SVMs) for Classification and Regression
SVMs are versatile models used for both classification (e.g., predicting if a stock will go up or down) and regression (SVR). They work by finding the optimal hyperplane that best separates data points into different classes or fits a regression line, often using a "kernel trick" to handle non-linear relationships by mapping data into higher-dimensional spaces. While powerful, they can be computationally intensive for very large datasets.
Deep Learning Architectures for Advanced Financial Prediction
Deep learning, a subset of machine learning involving neural networks with many layers, has emerged as a game-changer for financial time series forecasting, especially when dealing with large, complex datasets and long-term dependencies. Their ability to automatically learn hierarchical representations from raw data minimizes the need for manual feature engineering.
Recurrent Neural Networks (RNNs) and LSTMs
RNNs are specifically designed to process sequential data, making them naturally suited for time series. However, basic RNNs suffer from the vanishing gradient problem, limiting their ability to learn long-term dependencies.
- Long Short-Term Memory (LSTM) Networks: LSTMs are a special type of RNN designed to overcome the vanishing gradient problem. They achieve this through a sophisticated internal mechanism called "gates" (input, forget, output gates) that regulate the flow of information, allowing them to remember or forget information over long sequences. LSTMs are exceptionally effective for tasks like predicting stock prices, cryptocurrency movements, and macroeconomic indicators, where past events significantly influence future outcomes.
- Gated Recurrent Units (GRUs): GRUs are a simplified version of LSTMs, with fewer gates, making them computationally less intensive while often achieving comparable performance. They offer a good balance between complexity and predictive power for various financial forecasting tasks.
Convolutional Neural Networks (CNNs) in Financial Time Series
While traditionally associated with image processing, CNNs have found applications in financial time series by treating time series data as a 1D "image." They excel at identifying local patterns and features within segments of the time series data, which can then be combined to make predictions. For example, CNNs can detect specific chart patterns or short-term trends that precede significant price movements.
Transformer Networks
Originally developed for natural language processing, Transformer networks, particularly their attention mechanisms, are now being explored for time series forecasting. Attention allows the model to weigh the importance of different parts of the input sequence when making a prediction, potentially capturing complex long-range dependencies more effectively than RNNs or LSTMs. This architecture shows promise for handling highly volatile and complex financial data.
Essential Considerations for Implementing ML in Financial Forecasting
Building effective machine learning models for finance goes beyond simply choosing an algorithm. Several critical steps and considerations are paramount for success.
Data Preprocessing and Feature Engineering
The quality and relevance of your input data are arguably more important than the choice of algorithm. Financial data is often noisy, non-stationary, and prone to outliers.
- Data Cleaning: Handling missing values, correcting errors, and smoothing noisy data.
- Stationarity: Many time series models assume stationarity (constant mean, variance, and autocorrelation over time). Techniques like differencing are often applied to achieve this.
- Feature Engineering: Creating new, informative features from raw data. This is a crucial step for boosting model performance. Examples include:
- Technical indicators (e.g., Moving Averages, RSI, MACD).
- Lagged values of the target variable and other features.
- Volatility measures (e.g., historical volatility, implied volatility).
- Macroeconomic indicators, news sentiment, or alternative data (e.g., satellite imagery, credit card transactions).
Effective feature engineering can transform raw financial data into a rich set of predictors that capture market dynamics more accurately.
Model Evaluation and Validation
Robust evaluation is vital to ensure a model's true predictive power and avoid misleading results.
- Backtesting: Simulating the model's performance on historical data, crucial for assessing its viability under past market conditions. This must be done carefully to avoid look-ahead bias.
- Walk-Forward Validation: A more rigorous backtesting method where the model is retrained periodically on an expanding window of historical data, simulating real-world deployment.
- Performance Metrics: Beyond standard metrics like RMSE (Root Mean Squared Error) or MAE (Mean Absolute Error), financial forecasting often requires specific metrics like directional accuracy (predicting the correct direction of movement), Sharpe Ratio (for trading strategies), or Maximum Drawdown (for risk assessment).
Overfitting and Underfitting
These are common challenges in machine learning. Overfitting occurs when a model learns the training data too well, including its noise, and performs poorly on unseen data. Underfitting happens when a model is too simple to capture the underlying patterns.
- Mitigation Strategies: Techniques like cross-validation, regularization (L1, L2), dropout (for neural networks), early stopping, and increasing the amount of training data can help prevent overfitting.
Interpretability and Explainability (XAI)
In finance, the "black box" nature of complex ML models can be a significant hurdle. Regulators often require transparency, and financial professionals need to understand why a model makes a particular prediction to trust it and manage its risks effectively. Tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are gaining traction to provide insights into model decisions, improving model interpretability.
Practical Applications and Actionable Insights
The application of machine learning techniques for time series forecasting in finance is vast and continues to expand.
- Algorithmic Trading Strategies: ML models can predict short-term price movements, optimal entry/exit points, and identify arbitrage opportunities. This forms the backbone of modern algorithmic trading systems.
- Risk Management: Forecasting Value-at-Risk (VaR), predicting credit defaults, and identifying potential market crashes. ML helps financial institutions quantify and mitigate exposure to various risks.
- Portfolio Optimization: Predicting future asset returns and correlations to construct optimal portfolios that maximize returns for a given level of risk or minimize risk for a target return.
- Fraud Detection: Identifying anomalous patterns in transaction data that may indicate fraudulent activity, a critical application for financial security.
- Sentiment Analysis Integration: Combining structured financial data with unstructured data from news articles, social media, and analyst reports to capture market sentiment and improve predictions. This offers a holistic view of market drivers.
Overcoming Challenges in Financial Time Series Forecasting
Despite their power, applying ML to financial time series is not without significant challenges:
- Non-Stationarity and Regime Changes: Financial markets are constantly evolving. Models trained on past data may fail when market dynamics shift due to new economic policies, technological advancements, or unforeseen global events.
- High Noise-to-Signal Ratio: Financial data is notoriously noisy, with many irrelevant fluctuations masking the underlying patterns. Differentiating between true signals and random noise is a constant battle.
- Market Efficiency Hypothesis: The concept that all available information is already reflected in asset prices suggests that consistently beating the market using past data is difficult. ML models must find subtle, fleeting inefficiencies.
- Data Scarcity for Rare Events: Predicting "black swan" events or financial crises is challenging due to their infrequent occurrence, leading to limited training data.
- Regulatory and Ethical Considerations: The use of AI in finance raises concerns about fairness, bias, and accountability, necessitating robust governance frameworks.
Successfully navigating these challenges requires a deep understanding of both machine learning principles and financial market intricacies. It necessitates continuous model monitoring, adaptation, and a robust backtesting framework to ensure models remain effective in dynamic environments. Embrace these advanced techniques to elevate your financial decision-making and gain a significant edge in today's competitive landscape. For a deeper dive into specific implementation, consider consulting with experts in quantitative finance.
Frequently Asked Questions About ML in Financial Forecasting
What makes financial time series data uniquely challenging for machine learning?
Financial time series data presents several unique challenges. Firstly, it's often highly non-stationary, meaning its statistical properties (like mean and variance) change over time, making patterns difficult to learn. Secondly, it has a very low signal-to-noise ratio; true predictive signals are often buried under a lot of random fluctuations. Thirdly, financial markets are adaptive and subject to "regime changes" (sudden shifts in behavior due to economic events or policy changes), which can quickly invalidate previously learned patterns. Finally, the efficient market hypothesis suggests that all available information is already reflected in prices, making it inherently difficult to find persistent predictable patterns.
How do you choose the right machine learning model for a specific financial forecasting task?
Choosing the right machine learning model depends on several factors. For tasks requiring high interpretability or simpler linear relationships, traditional regression or tree-based models like Random Forests might be suitable. For capturing complex non-linear dependencies and long-term memory in sequential data, deep learning models like LSTMs or Transformers are often preferred. Consider the volume and velocity of your data, the desired prediction horizon (short-term vs. long-term), and the computational resources available. It's often best practice to start with simpler models as a baseline and progressively explore more complex ones, always prioritizing robust validation through backtesting and walk-forward analysis.
Is it possible to achieve 100% accuracy in financial market predictions using ML?
No, achieving 100% accuracy in financial market predictions using machine learning is not realistic or possible. Financial markets are inherently complex, influenced by countless variables, including human psychology, geopolitical events, and unexpected news, many of which are unpredictable. Machine learning models can identify patterns and probabilities, offering a statistical edge, but they cannot perfectly foresee the future. The goal is to develop models that provide a consistent, albeit small, predictive advantage over random chance, leading to profitable outcomes over the long term, rather than seeking unattainable perfect accuracy.
What role does data quality play in the success of machine learning models in finance?
Data quality is absolutely paramount to the success of machine learning models in finance. "Garbage in, garbage out" perfectly applies here. No matter how sophisticated the machine learning algorithm, if the input data is inaccurate, incomplete, noisy, or improperly preprocessed, the model's predictions will be unreliable. Clean, accurate, and relevant data, coupled with meticulous feature engineering, significantly enhances a model's ability to learn meaningful patterns and generalize well to unseen data, directly impacting the profitability and reliability of financial forecasting systems.
How can ethical considerations and regulatory compliance be addressed when deploying ML models in finance?
Addressing ethical considerations and regulatory compliance in financial ML models is crucial. This involves focusing on model interpretability to understand how decisions are made, avoiding bias in training data to prevent discriminatory outcomes (e.g., in credit scoring), and ensuring transparency in model operations. Financial institutions must comply with regulations like GDPR, CCPA, and industry-specific rules (e.g., Dodd-Frank Act). Implementing robust governance frameworks, performing regular model audits, maintaining clear documentation, and ensuring human oversight are essential steps to build trustworthy and compliant AI systems in finance.
0 Komentar