Complete Guide
Are you grappling with overwhelming volumes of data, struggling to extract timely and actionable insights? In today's data-driven landscape, manual data analysis is rapidly becoming a bottleneck, hindering agility and strategic decision-making. This comprehensive guide delves into how to use machine learning for automating data analysis tasks, transforming your approach from laborious manual processes to efficient, intelligent, and scalable operations. Discover how integrating machine learning can unlock unprecedented levels of efficiency, enhance accuracy, and drive profound data-driven decisions, moving beyond traditional statistical analysis to uncover deeper patterns and predictive capabilities. This is not just about speed; it's about superior insight generation.
The Imperative of Automation in Modern Data Analysis
The sheer scale and complexity of modern datasets, often characterized by the "three Vs" – Volume, Velocity, and Variety – make traditional, human-centric data analysis methods increasingly inadequate. Businesses, researchers, and organizations alike are drowning in information, yet starved for true understanding. The manual manipulation of spreadsheets, the painstaking creation of reports, and the struggle to identify subtle trends across vast datasets consume valuable resources and introduce significant delays. This is precisely where the power of automating data analysis tasks with machine learning becomes indispensable.
Challenges of Traditional Data Analysis
- Scalability Issues: Manual processes simply cannot keep pace with the exponential growth of big data.
- Time Consumption: Data cleaning, transformation, and initial exploration are notoriously time-intensive, delaying insight generation.
- Human Error: Repetitive manual tasks are prone to inconsistencies and mistakes, compromising data integrity.
- Limited Scope: Human analysts can only process so much information, often missing complex pattern recognition or subtle correlations.
- Lack of Real-Time Insights: Manual methods are inherently retrospective, failing to provide the immediate insights needed for dynamic environments.
Understanding the Core Concepts: ML & Data Analysis
Before diving into the "how," it's crucial to grasp the fundamental relationship between machine learning and data analysis. Machine learning is not just a tool; it's a paradigm shift in how we interact with and learn from data.
What is Machine Learning?
Machine learning (ML) is a subset of artificial intelligence that empowers systems to learn from data, identify patterns, and make decisions or predictions with minimal human intervention. Unlike traditional programming where rules are explicitly coded, ML algorithms learn these rules directly from the data itself. This learning can be categorized into several types:
- Supervised Learning: Uses labeled datasets to train models to predict outcomes or classify data (e.g., predicting sales figures, classifying emails as spam).
- Unsupervised Learning: Works with unlabeled data to discover hidden patterns or structures (e.g., customer clustering, anomaly detection).
- Reinforcement Learning: Trains agents to make a sequence of decisions by interacting with an environment, learning through trial and error (e.g., autonomous driving).
The Synergy: Where ML Meets Data Analysis
When ML meets data analysis, it creates a powerful synergy. Data analysis traditionally focuses on describing past events and understanding relationships. Machine learning elevates this by enabling predictive analytics and prescriptive actions. It automates repetitive, complex, and high-volume aspects of the analytical pipeline, allowing human analysts to focus on higher-value tasks like strategic interpretation and action planning. ML algorithms can automatically identify outliers, segment data, forecast trends, and even generate natural language summaries, pushing the boundaries far beyond simple statistical analysis.
Key Stages of Automating Data Analysis with Machine Learning
Automating data analysis with machine learning isn't a single step but a structured process involving several critical stages. Each stage benefits immensely from ML capabilities, enhancing efficiency and accuracy.
1. Data Collection and Ingestion Automation
The journey begins with data. Manually collecting and ingesting data from disparate sources is time-consuming and error-prone. Automation here involves setting up robust data pipelines that automatically pull data from various sources (databases, APIs, web logs, IoT sensors) and load it into a centralized repository for analysis.
- Automated Data Connectors: Tools that seamlessly integrate with diverse data sources.
- Real-time Streaming: Using technologies like Apache Kafka or AWS Kinesis to ingest data as it's generated.
- Web Scraping Automation: Deploying bots to collect data from websites at scheduled intervals.
2. Automated Data Cleaning and Preprocessing
Raw data is rarely clean. It often contains missing values, inconsistencies, errors, and outliers. This phase, traditionally one of the most laborious, can be significantly automated using ML techniques.
- Missing Value Imputation: ML models (e.g., K-Nearest Neighbors, regression models) can predict and fill in missing values more accurately than simple averages.
- Outlier Detection: Unsupervised learning algorithms like Isolation Forest or One-Class SVM can automatically identify unusual data points that might skew analysis.
- Data Transformation: Automated scaling, normalization, and encoding of categorical variables prepare data for model consumption.
- Deduplication and Consistency Checks: ML-powered fuzzy matching algorithms can identify and merge duplicate records or correct inconsistent entries.
3. Automated Feature Selection and Engineering
Features are the individual measurable properties or characteristics of the phenomenon being observed. Effective feature engineering is crucial for model performance but is often a manual, iterative, and expert-driven process. ML can automate this by:
- Automated Feature Creation: Generating new features from existing ones (e.g., combining two columns, deriving ratios) using algorithms that explore potential combinations.
- Feature Selection Algorithms: Using techniques like Recursive Feature Elimination (RFE) or Lasso Regression to automatically identify the most impactful features, reducing dimensionality and improving model efficiency.
- Dimensionality Reduction: Algorithms like Principal Component Analysis (PCA) or t-SNE can automatically reduce the number of features while preserving essential information, making data processing more manageable.
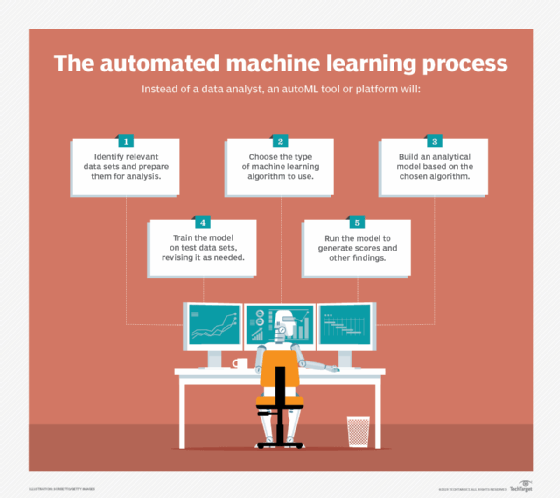
4. Automated Model Selection and Training
Choosing the right machine learning algorithm and fine-tuning its parameters (hyperparameters) for a specific dataset is a complex task. AutoML (Automated Machine Learning) platforms have emerged to automate this entire process.
- Algorithm Selection: AutoML can automatically experiment with various algorithms (e.g., Linear Regression, Random Forest, Gradient Boosting, Neural Networks) to find the best fit for your data and problem type.
- Hyperparameter Tuning: Instead of manual trial and error, techniques like Grid Search, Random Search, or Bayesian Optimization automatically find the optimal set of hyperparameters that maximize model performance.
- Automated Model Training: Once the algorithm and hyperparameters are selected, the model is automatically trained on the prepared dataset, minimizing human intervention. Learn more about different machine learning algorithms.
5. Automated Model Evaluation and Validation
Once trained, a model's performance must be rigorously evaluated to ensure its reliability and generalization capabilities. Automation here involves setting up pipelines that automatically assess model metrics (e.g., accuracy, precision, recall, F1-score for classification; RMSE, MAE for regression) and perform cross-validation.
- Automated Metric Calculation: Scripts can automatically compute performance metrics against a validation set.
- Cross-Validation Loops: Automated k-fold cross-validation ensures the model's robustness and prevents overfitting.
- Bias Detection: Advanced ML tools can even automatically check for potential biases in model predictions.
6. Automated Insight Generation and Reporting
The ultimate goal of data analysis is to generate actionable insights. Machine learning can automate this final step, moving beyond raw data output to digestible, intelligent reports and visualizations.
- Automated Data Visualization: ML can identify key trends and automatically generate appropriate charts and graphs, often integrated with data visualization tools like Tableau or Power BI.
- Natural Language Generation (NLG): Advanced ML models can translate complex data insights into human-readable text, automating the creation of executive summaries or detailed reports.
- Alerting Systems: ML models can be set up to automatically trigger alerts when anomaly detection identifies critical deviations or when predictive analytics forecasts a significant event.
- Dashboard Updates: Automated model deployment ensures that live dashboards are continually updated with fresh predictions and insights.
Practical Applications and Use Cases
The application of machine learning for automating data analysis is vast and touches almost every industry. Here are a few compelling examples:
- Customer Segmentation & Personalization: ML clustering algorithms automatically group customers based on behavior, demographics, and purchasing patterns, enabling highly targeted marketing campaigns and personalized product recommendations. This automates a core business intelligence task.
- Predictive Maintenance: In manufacturing or logistics, sensors collect vast amounts of data. ML models automatically analyze this data to predict equipment failures before they occur, allowing for proactive maintenance and reducing downtime. This is a prime example of real-time predictive analytics.
- Fraud Detection: Financial institutions use ML to automatically identify suspicious transactions by detecting anomaly detection patterns that deviate from normal behavior, significantly reducing financial losses.
- Market Trend Analysis and Forecasting: Retailers and financial analysts use ML to automatically analyze historical sales data, economic indicators, and social media trends to forecast future demand, stock prices, or market shifts, informing inventory management and investment strategies.
- Automated Content Categorization and Tagging: For media companies or large document repositories, ML-powered Natural Language Processing (NLP) can automatically categorize articles, tag content, and summarize text, making information more discoverable and manageable.
Tools and Technologies for ML-Powered Data Automation
Leveraging machine learning for data analysis automation requires the right set of tools and platforms. Here's a glimpse into the ecosystem:
- Programming Languages: Python (with libraries like Pandas, NumPy, Scikit-learn, Statsmodels) and R are the dominant choices due to their extensive ML and statistical libraries.
- Machine Learning Frameworks: TensorFlow, PyTorch, and Keras provide robust foundations for building and deploying complex ML models, especially for deep learning.
- Cloud-Based ML Platforms:
- AWS Sagemaker: A fully managed service that covers the entire ML lifecycle, from data processing to model deployment.
- Google Cloud AI Platform: Offers a suite of ML services, including AutoML capabilities for automated model building.
- Azure Machine Learning: Microsoft's offering for building, training, and deploying ML models at scale.
- AutoML Tools: Beyond cloud offerings, dedicated platforms like H2O.ai, DataRobot, and TPOT automate algorithm selection and hyperparameter tuning.
- Data Orchestration Tools: Apache Airflow, Prefect, and Dagster help schedule, monitor, and manage complex data pipelines that feed ML models.
- Data Visualization Tools: While not ML tools themselves, Tableau, Power BI, and Looker seamlessly integrate with ML outputs to create dynamic, automated dashboards.
Best Practices for Successful Implementation
While the allure of automation is strong, successful implementation of ML for data analysis requires a strategic approach.
- Define Clear Objectives: Before diving into algorithms, precisely articulate what problems you aim to solve and what insights you need. What data-driven decisions do you want to enable?
- Ensure Data Quality: "Garbage in, garbage out" applies emphatically to ML. Invest in robust data cleaning and validation processes. Automated cleaning helps, but human oversight is still critical initially.
- Start Small and Iterate: Begin with pilot projects that have a clear scope and measurable outcomes. Learn from these initial implementations and iterate, gradually expanding the scope of automation.
- Monitor Model Performance Continuously: ML models are not "set-and-forget." Data distribution can change over time (data drift), leading to model degradation. Implement automated monitoring to detect performance decay and trigger retraining.
- Focus on Interpretability (where needed): For critical applications, understanding why a model makes a certain prediction is crucial. While some advanced models are "black boxes," techniques like SHAP or LIME can provide insights into their decisions.
- Foster a Data-Driven Culture: Technology alone isn't enough. Encourage your team to embrace data, trust automated insights, and use them to inform their actions.
- Secure and Govern Data: As you automate, ensure robust data governance, privacy, and security measures are in place, especially when dealing with sensitive information.
Challenges and Considerations
Despite its immense benefits, automating data analysis with machine learning comes with its own set of challenges:
- Data Privacy and Security: Handling large volumes of sensitive data requires stringent security protocols and compliance with regulations like GDPR or CCPA.
- Model Bias and Fairness: If the training data is biased, the ML model will perpetuate and even amplify those biases, leading to unfair or discriminatory outcomes. Careful attention to data diversity and model validation is crucial.
- Computational Resources: Training complex ML models, especially deep learning ones, can be computationally intensive, requiring significant hardware or cloud infrastructure.
- Skill Gap: While automation reduces manual effort, it requires a new set of skills – data scientists, ML engineers, and data architects – to build, deploy, and maintain these systems.
- Integration with Existing Systems: Integrating new ML automation pipelines with legacy systems can be complex and require significant engineering effort.
Frequently Asked Questions
What is the primary benefit of using machine learning for data analysis automation?
The primary benefit is a dramatic increase in efficiency and scalability, allowing organizations to process vast amounts of big data rapidly and extract insights that would be impossible or prohibitively expensive with manual methods. This leads to faster, more accurate data-driven decisions and significant competitive advantages through predictive analytics and advanced pattern recognition.
Can small businesses leverage ML for data analysis?
Absolutely. While large enterprises might have dedicated data science teams, the rise of user-friendly AutoML platforms and accessible cloud-based ML services has democratized access to machine learning. Small businesses can now leverage these tools to automate tasks like customer segmentation, sales forecasting, and even basic anomaly detection without needing extensive in-house expertise. Starting with clear, well-defined problems is key.
How long does it take to implement ML automation for data analysis?
The timeline varies greatly depending on the complexity of the task, the quality of your existing data, and the resources available. Simple automation projects (e.g., automating a specific reporting task) might take weeks, while comprehensive enterprise-wide data pipelines with advanced model deployment could span several months to over a year. It's often an iterative process, with initial value delivered relatively quickly and continuous refinement over time.
What are the risks of relying too heavily on automated data analysis?
Over-reliance can lead to several risks: a lack of human intuition and critical thinking, which might miss nuances or context that automated systems overlook; the perpetuation of biases if models are trained on unrepresentative data; and the challenge of interpreting "black box" models for critical decisions. It's essential to maintain human oversight, regularly validate models, and use automation as an augmentation, not a replacement, for human expertise.
Embrace the future of data analysis. By strategically integrating machine learning, your organization can move beyond reactive reporting to proactive, intelligent insights, truly harnessing the power of your data. Ready to transform your data analysis capabilities? Consider investing in the right tools and expertise to embark on this powerful journey of automation and discovery.
0 Komentar